
Data Security in Software
Security is our top most priority!
Data Security is all about CIA
Confidentiality, Integrity, Availability.
Data Confidentiality
Data confidentiality needs to cover data at rest and data in transit.
Data Integrity
Data integrity can be ensured as a preventive and corrective measure.
Data Availability
Data availiablity is ensured by protection and in case of failure through a backup.
In Transit
Data during transit from Server-to-Browser and from Browser-to-Server is 100% encrypted using HTTPS Protocol. This is an industry standard for data encryption during transfer.
Processing
All the code written goes for a quality check to ensure it meets performance, security and design parameters. To ensure this and keep track we use GIT for version control.
Protection
Jamku servers are protected from DOS attacks, by blocking malicious user agents based on machine learning and temporary IP blocking based on requests.
At Rest
All data resides in the database. The database is encrypted and stored on hard disk using hardware encryption. Thus ensuring full encryption.
Designings
Data security is considered as a factor even right from designing phase. Whenever a new feature is planned, the dedicated team of CAs and Engineers prepare a blueprint.
Backup
We have 3 plan backup – 2 are automated process, 1 is manual process. Plan A backup is kept in AWS. Plan C backup is kept in our office NAS Box. *Plan B is a secret 🙂 this is also protection measure.
How is my Data Stored?
This is the most common question we get, so here’s how your data is stored.
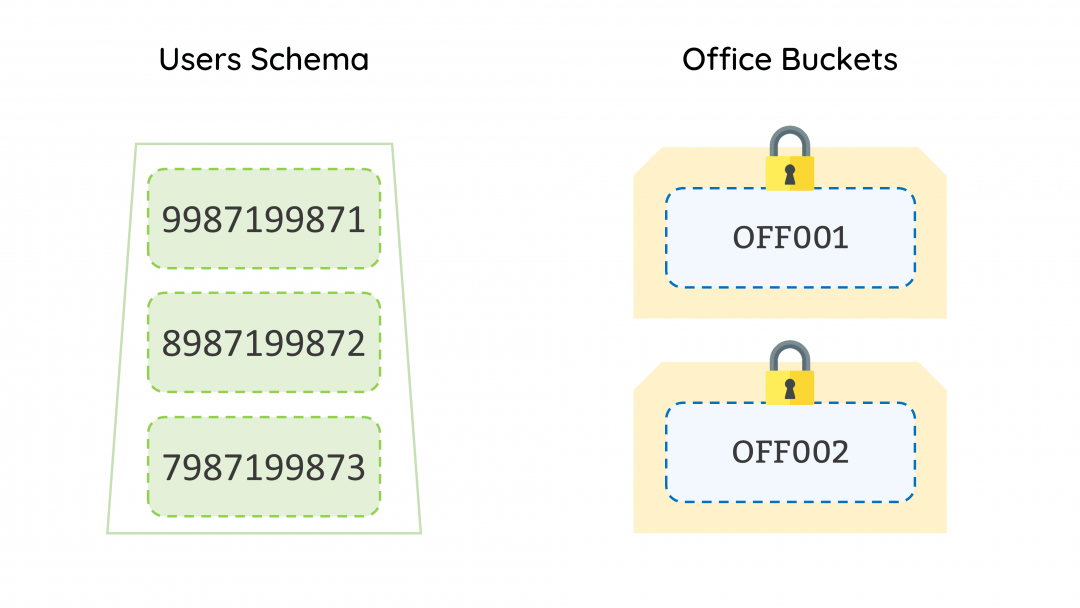
All the data relating to your office is stored in Buckets (Bucket is a metaphor to avoid using the technical jargons). All these buckets are locked until the user logs into the software.
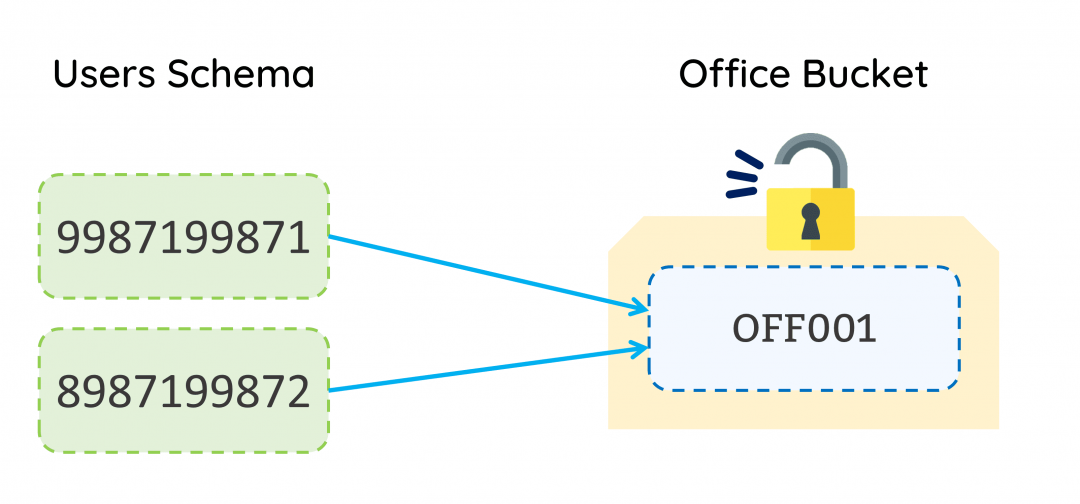
When a user logs in to jamku, system checks which all buckets the user is authorised for. If the system finds a single office bucket, it will unlock the bucket and allow the user to interact with the data inside the bucket based on the permissions assigned to the user.
In case, the system finds that the user is authorised to access more than one bucket, then it prompts the user which bucket it wants to login into. Thus, ensuring no unauthorised access to the bucket is possible.
Where is my Data Saved?
Ok, lets answer another commonly asked question
We have purchased the servers from one of the biggest cloud/web hosting company. They store the data in their Tier 3 Data Center which is located in Mumbai. In case of any issue with Mumbai Data Centre, the server is migrated to Banglore Data Centre.
Apart from the main data storage, we keep the backup with AWS, which has a data centre in Mumbai.
What happens if the server goes down?
We aim for 99% uptime but server downtime is inevitable because the server will go down for some reason. Here are some of the safeguards that we have in place.
Preventive Control
KVM architecture
The server sits on top of the KVM architecture which makes it resilient to hardware failures. Every hardware has a redundancy. Eg – in case of a hard disk failure the RAID configuration will kick in and activate the failover SSD.
Monitoring Control
Uptime Robot
We have implemented Uptime Robot to monitor the server uptime. If the server goes down, it immediately notifies the entire development team of Jamku. We then figure out the issue and get the server up and running.
Corrective Control
Backup
In an unfortunate event of total failure, we shall restore the backup from our Plan A. If Plan A fails we have a Plan B backup restoration. In case of Plan B failure, the data is restored from Plan C. This may result in data loss of up to 3 hours.
We believe in transparency, hence our uptime monitoring is publicly available for curious minds 🙂
Why 99% and not 100%?
Server software needs to be updated on a regular basis to maintain the best in class security and performance. When the server software is updated, Jamku becomes temporarily unavailable. This will, however, not impact your office functioning because this is scheduled to run at night. Apart from server software updates, we also undertake database tuning and optimization, this also results in a downtime. Be rest assured, these activities are also undertaken at night. Updating the Jamku to next version, may also result in downtime of 1-2 minutes.
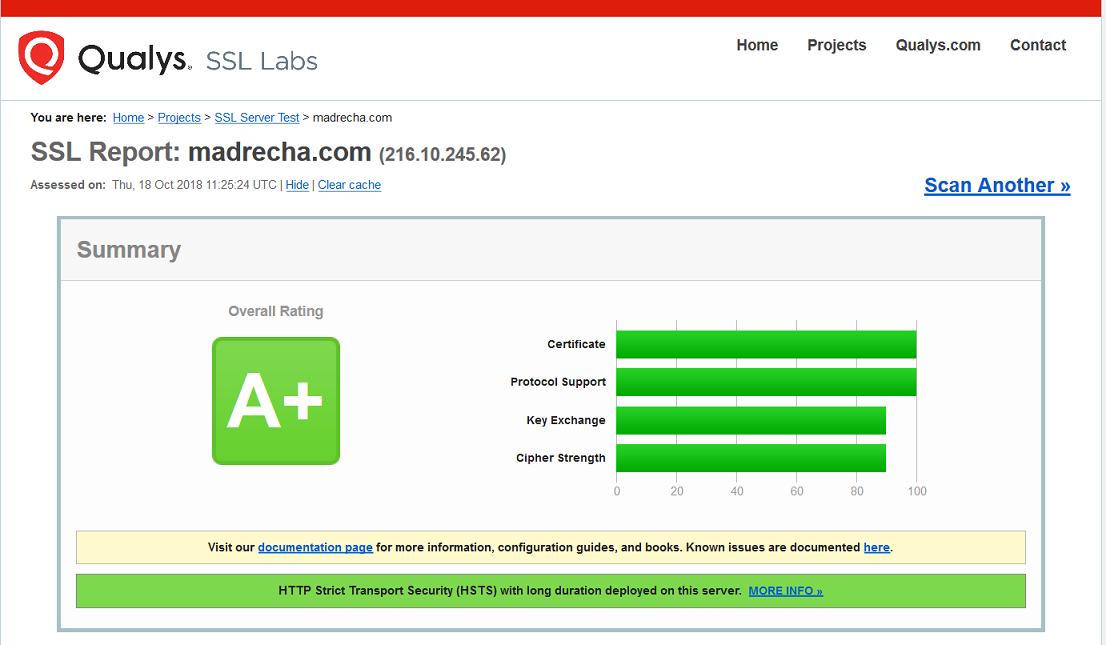
Qualys, the industry standard to test the HTTPS, aka encryption during data in transit rated us “A+”.
For FREE Jamku Demo,
Inquire here!OR
Call us on
✔ 99871 06585 (CA Priya Madrecha)
✔ 80976 78068 (Shweccha Jain)
Email us on jamku.support@madrecha.com